- OOTDiffusion:它设计了一个服装搭配UNet来学习服装细节特征,并通过提出的搭配融合技术,将服装特征与目标人体精确对齐,无需冗余的变形过程。其侧重于通过搭配融合技术和搭配丢失来增强虚拟试穿的可控性,无需显式的特征对齐或变形过程。
- AnyDoor:展示了在0设置下生成高质量、多样化的图像的能力,并且不需要针对每个对象进行参数调整。而且AnyDoor提供了一个更广泛的图像编辑框架,允许用户在新场景中定制和移动对象,而不仅限于虚拟试穿。
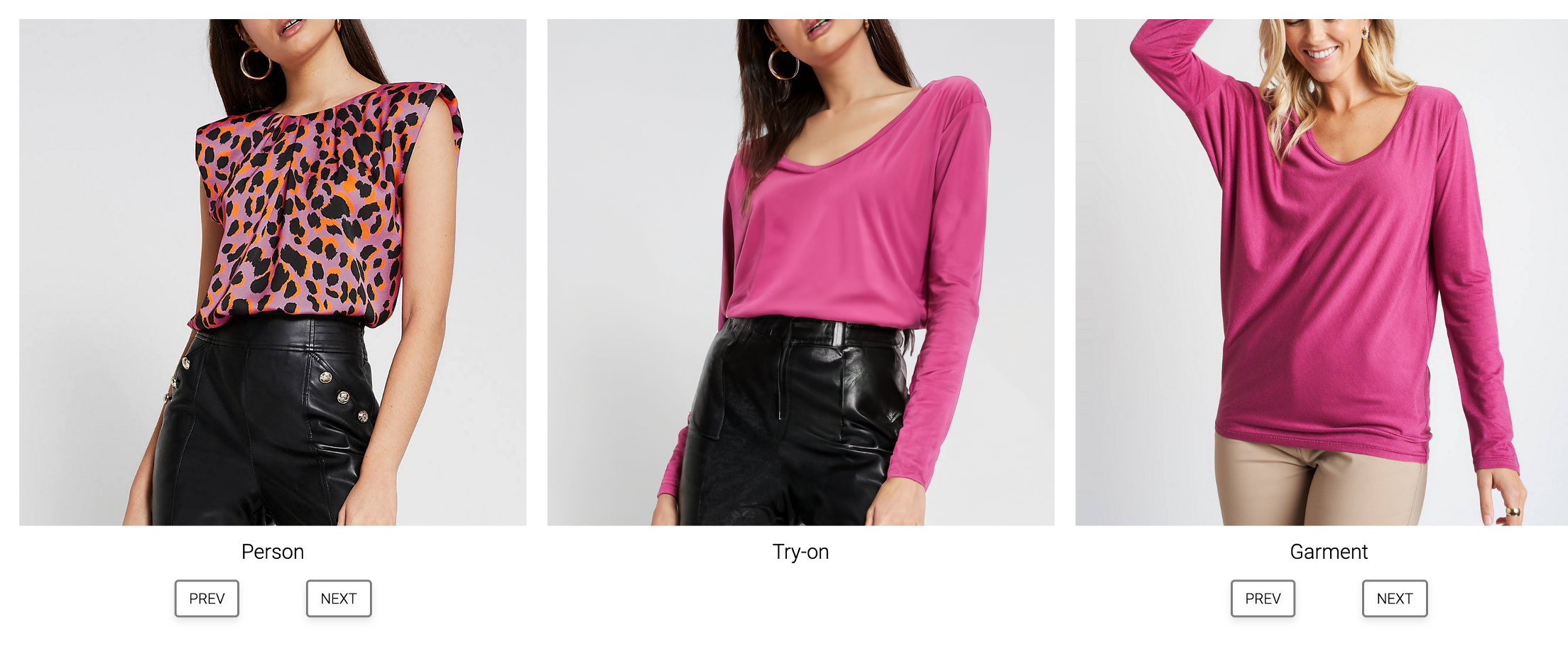
- TryOnDiffusion:该方法在4百万图像对上进行训练,每个样本包括同一人在不同姿势下穿着相同服装的两幅图像。TryOnDiffusion专注于处理大量的遮挡和姿势变化,通过Parallel-UNet架构实现服装的隐式变形和混合。
| OOTDiffusion | AnyDoor | TryOnDiffusion |
|---|---|---|
 |
 |
 |
OOTDiffusion:https://github.com/levihsu/OOTDiffusion/tree/main
AnyDoor:https://github.com/ali-vilab/AnyDoor
TryOnDiffusion:https://github.com/tryonlabs/tryondiffusion
TryOnDiffusion Doc: https://tryondiffusion.github.io/